
Rylah's Study & Daily Life
PyTorch 03. DNN - Heart Disease Dataset 본문
인간의 두뇌 : 1000억 개의 뉴런들이 100조 개의 시냅스로 연결
뇌 학습
- 인간의 오감을 담당하는 센서를 통해 외부 정보를 얻음
- 얻어진 정보를 뉴런들이 받아서 계산
- 각각의 뉴런들이 계산한 정보는 시냅스를 통해 다른 뉴런들에게 전달됨
- 이 뉴런의 계산 정보는 근처의 시냅스에 저장됨
심층 신경망(Depp Neural NetWork : DNN)
- 인공신경망(Artificial Neural Network)의 한 종류
- 다양하고 복잡한 비선형적 관계를 학습할 수 있음

- 복잡한 비선형 관계도 정확한 모델이 가능함
-> 실제로 기업들이 제공하는 서비스를 담당하는 DNN의 은닉층 개수는 100개가 훨씬 넘음
- DNN 구조 안에 사용되는 뉴런과 시냅스의 숫자도 매우 많음
-> 이러한 DNN을 처리하기 위해서는 큰 규모의 데이터 서버를 사용함
뉴런의 출력 계산 과정

- Xk : 입력 뉴런 K의 출력 값
- Wk : 시냅스 k의 가중치
- b : 편향 값
활성화 함수
- AI 반도체
-> Multiply-and-Accumulate (MAC) 계산기들은 많은 숫자를 사용하고 이들을 모두 병렬 계산에 투입함
-> Multiply-and-Accumulate (MAC)의 결과를 바로 출력 값으로 사용하지 않고, 활성화 함수를 거침
1. 선택된 활성화 함수에 Mulitiply and ADD (MAC) 결과를 입력값으로 사용
2. 그 함수가 만들어내는 값이 최종 뉴런 N의 출력 값이 됨
- 활성화 함수는 종류가 다양하며 장단점과 쓰임새가 다르다
-> ReLU, Linear, Sigmoid...
역전파 알고리즘(Backpropangation Algorithm)

- 가장 보편적인 인공신경망 학습 알고리즘
-> 지도 학습 (Supervised Learning)에 사용
-> 다층 순행 공급 (Feedforward) 신경망에서 사용
- 순방향
-> 입력값 제시 후 출력 값을 계산 (왼쪽 --> 오른쪽(=Forward)
=> 정답과 출력의 차이인 오차에 근거
-> 각각의 뉴런에 계산 값을 저장
- 역방향
-> 출력 값이 주어지면 신경망의 가중치 보정은 오른쪽에서 왼쪽으로 (=Backward)
-> 순방향의 계산 결과를 활용
역전파 알고리즘: 역방향 계산
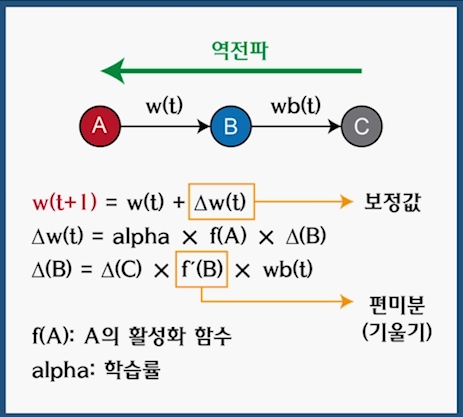
알고리즘 원리
- 입력이 신경망을 통과하여 입력값을 계산
- 출력은 정답과 다를 수 있음
- 오차 = 정답과 출력의 차이
- 오차에 비례하여 출력층의 가중치를 보정한다
- 그다음 은닉층의 가중치를 보정
- 보정치는 '편미분'으로 계산
가중치 보정 방법
- 델타 값을 구해서 보정 : Δw(t)
- 델타는 Δ(B)에 영향을 받음
- ΔB는 C를 통해 계산 : 역전파가 필요하다
alpha : 학습률
- 인간이 조절하는 값
- 매번 보정해주는 크기를 얼마 정도로 할 것인지를 지정하고, 보정 값에 학습률을 곱함
- 학습률이 낮을수록, 학습 시간은 느려지지만 정확도는 높아짐
f(A)
- 뉴런 A의 출력 값
delta(B)
- 뉴런 B의 경사 값
- 뉴런 B와 순방향으로 연결된 뉴런 C가 사용됨
기울기 유실(Vanishing Gradient)
증상
- 아무리 새로운 데이터를 주어도 인공신경망이 학습을 하지 않는 것
- 바꾸어 말하면 신경망 가중치가 더 이상 변하지 않음
- 원인 중 하나는 활성화 함수 때문 : sigmoid(x) = 1 / (1 + e^(-x))
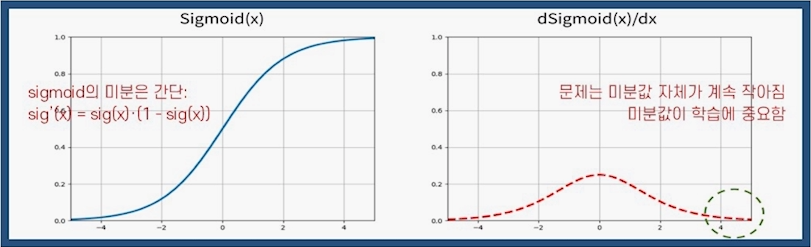
sigmoid 미분은 간단한 미분 계산이다.
기울기의 의미
- 가중치를 보정할 때 사용한 편미분이 기울기이다
- 기울기 값이 0이 되면, 보정치도 0이 된다.
- x값이 커질수록 기우기는 0에 수렴한다.
=> x : 뉴런의 출력 값
- 학습이 많이 진행되어 후반부에 이르면 대부분의 뉴런의 출력 값이 커지고 편미분, 기울기의 값도 0에 가까워진다.
- 한 뉴런의 편미분, 즉 기울기는 입력값에 대한 '감도', 즉 sensitivity이다.
해결 방법 : 활성화 함수 교체


14가지 항목의 내용
age : 나이
sex : 성별 (0: 여성, 1: 남성)
cp : 가슴통증 유형(4가지)
trestbps : 안정 혈압
chol : 좋은 콜레스테롤 수치 (HDL)
fbs : 공복 혈당(Fasting blood sugar) (0 : 120보다 낮음 , 1 : 120보다 높음)
restecg : 안정 심전도 (3가지, 0 : 정상)
thalach : 최대 심박수
exang : 운동 시 협심 증상 (0 : 아니오, 1 : 예)
oldpeak : 운동시 유발되는 ST depression

slope : 운동시 ST segment 기울기 (1 : 양수, 2 : 0 , 3 : 음수)
ca : 형광 투시가 되는 주요 혈관의 수 (0 ~ 3 / 0은 막힘)
thal : 결함 종류 (3 : 정상 , 6/7 : 비정상)
HeartDisease : 심장병(0 : 아님 1 : 심장병)
6가지 패키지가 필요
pandas, numpy, matplotlib, seaborn, pytorch, scikit-learn

데이터 4분할
- 각 데이터는 입력 값, 출력값, 정답을 소유
- 인공 신경망은 입력값을 받아 순방향(왼->오)으로 진행하며 출력값을 계산
- 출력값이 3.5이라면 정답 3과 오류 0.5를 발생
- 역전파하면서 뉴런과 시냅스의 가중치를 보정
- 학습용/평가용, 입력값/ 출력값으로 분할
- 나누는 순서는 상관 없음
Z-점수 정규화 이론
머신러닝 알고리즘
- 데이터의 특정 패턴을 찾음
- 새로운 값을 예측
심장병 데이터의 예
- 안정 혈압 : 94 ~ 200
- 올드 피크 : 0 ~ 6.2
-> 값의 범위 차이가 심함
-> 기계 학습을 할 때 범위가 더 넓은 요소가 큰 영향을 미친다.
정규화가 필요한 이유가 이와 같다.
Z-점수 = (X - 평균) / 표준편차
- 평균은 0, 표준편차는 1이 ㅗ디게 함
활용 예
- A는 SAT 시험에서 1800 (out of 2400)을 받음
- B는 ACT 시험에서 24 (out of 36)을 받음
- SAT 평균은 1500 표준편차는 300
- ACT 평균은 21, 표준편차는 5
- A의 Z-점수는 1, B는 0.6
- B가 더 못했다.

특이점은 기계학습에 도움이 안될 가능성이 존재


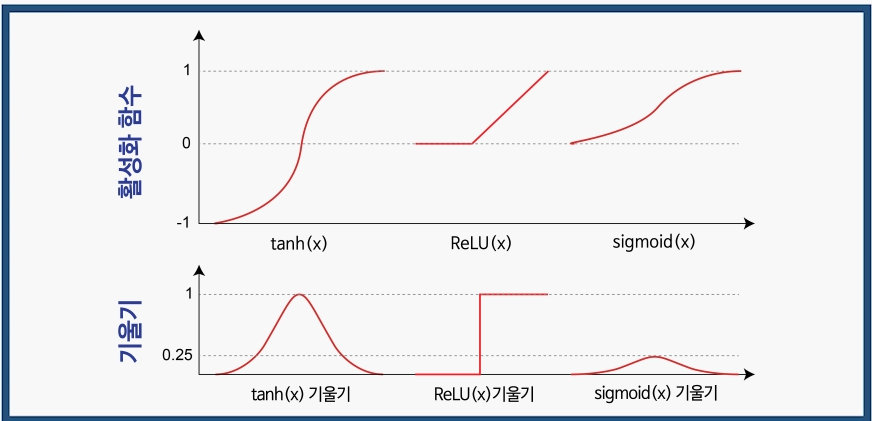
Tanh
DNN 은닉층에서 Tanh를 많이 사용
Sigmoid 함수의 기울기 유실 문제를 보완한다.

Sigmoid
딥 러닝에서 가장 많이 쓰이는 활성화 함수
위 그림은 로지스틱 함수



정확한 진단을 한눈에 볼 수 있는 것이 혼동 행렬

F1 정수 이론
Recall, Precision 을 이용한 조화 평균
역수를 산술 평균한 평균
평균의 비중을 모두 비슷하게 맞춰주는 효과가 있다.
# 파이썬 패키지 수입
import pandas as pd # pandas는 2차원 테이블에 특화된 패키지 (행,열 구성)
import matplotlib.pyplot as plt # 그래프 그릴 때 사용
import seaborn as sns # matplot 과 연동 flot을 만들어 줌
from time import time # 총 걸린 시간 계산
import torch
from torch import nn # torch -> nn use 층 구조 제공
from sklearn.model_selection import train_test_split # 심장병 데이터를 학습용, 평가용으로 나눌 때 사용
from sklearn.preprocessing import StandardScaler # Z점수 정규화를 할 때 사용
from sklearn.metrics import f1_score # 정확도를 판단할 때 사용
# 하이퍼 파라미터
INPUT_DIM = 13 # 총 14개의 파라미터 중 13개가 입력 요소
MY_HIDDEN = 1000 # DNN의 은닉 층에서 몇개를 사용할 지 결정 (DNN 규모)
MY_EPOCH = 1000 # 몇 번 반복해서 학습할 것인지 지정
# 추가 옵션 정리
pd.set_option('display.max_columns', None) # pandas의 display.max_columns 옵션을 off , 기본 값은 on,
# pandos가 dataframe을 출력 할 때 생략해버림, 생략 없이 하기 위해서 끔
torch.manual_seed(111) # pytorch의 씨앗을 정함 임의의 수를 정하는 알고리즘, 랜덤 시드값을 주기 위함
import numpy as np
np.random.seed(111) # numpy의 랜덤 시드값, 임의의 수 생성 및 지정
# 데이터 파일 읽기
# 결과는 pandas의 데이터 프레임 형식
raw = pd.read_csv('heart.csv')
# 데이터 원본 출력
print('원본 데이터 샘플 10개')
print(raw.head(10))
print('원본 데이터 통계')
print(raw.describe()) # 통계를 보여주는 describe
# 데이터를 입력과 출력으로 분리
X_data = raw.drop('target', axis=1)
Y_data = raw['target']
names = X_data.columns # 데이터의 이름들을 따와서 저장
print(names)
# 데이터를 학습용과 평가용으로 분리
X_train, X_test, Y_train, Y_test = \
train_test_split(X_data, Y_data, test_size=0.3) # 데이터를 무작위로 추출
# 최종 데이터 모양
print('\n학습용 입력 데이터 모양 : ', X_train.shape)
print('학습용 출력 데이터 모양 : ', Y_train.shape)
print('평가용 입력 데이터 모양 : ', X_test.shape)
print('평가용 출력 데이터 모양 : ', Y_test.shape)
# 입력 데이터 Z-점수 정규화
# 결과는 numpy의 n-차원 행렬 형식
scaler = StandardScaler() # StandardScaler를 짧게 정의
X_train = scaler.fit_transform(X_train) # fit_transform을 사용해서 13개의 요소를 한번에 Z-점수 평균화 진행
X_test = scaler.fit_transform(X_test) # 평가용 데이터에도 같은 Z-점수 평균화 진행
print('전환 전 : ', type(X_train))
# 호환이 완벽하지 않아서 자료 형변환이 필요함
# numpy에서 pandas로 전환
# header 복구가 필요 => 그래서 names를 미리 따둬야 한다.
X_train = pd.DataFrame(X_train, columns=names)
X_test = pd.DataFrame(X_test, columns=names)
print('전환 후 : ', type(X_train))
# 정규화 된 학습용 데이터 출력
# count : 갯수 , mean : 평균, std : 표준편차 : 거의 1
print('\n정규화된 학습용 데이터 샘플 10개')
print(X_train.head(10))
print('정규화된 학습용 데이터 통계')
print(X_train.describe())
# 핛브용 데이터 상자 그림
sns.set(font_scale=2)
sns.boxplot(data=X_train, palette="colorblind")
# plt.show()
# PyTorch DNN을 Sequential 모델로 구현
model = nn.Sequential(
nn.Linear(INPUT_DIM, MY_HIDDEN), # 입력층 , 첫번째 은닉층 추가 , 13 , 1000 , multiply Accumulate (선형 1차 방정식)
nn.Tanh(),
nn.Linear(MY_HIDDEN, MY_HIDDEN), # 두번째 은닉층 뉴런 계산
nn.Tanh(),
nn.Linear(MY_HIDDEN, 1), # 최종 출력층은 하나
nn.Sigmoid()
)
# DNN 요약
print('\nDNN 요약')
print(model)
# 총 파라미터 수 계산
total = sum(p.numel() for p in model.parameters())
print('총 파라미터 수: {:,}'.format(total))
# 최적화 함수와 손실함수 지정
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 최적화 함수 SGD
criterion = nn.MSELoss() # 손실함수 MSE 지정
# 학습용 데이터 전환
# pandas dataframe에서 Pytorch 텐서로
print('전환 전: ', type(X_train))
X_train = torch.tensor(X_train.values).float() #모든 데이터를 소수로 변경하는 코드 포함
Y_train = torch.tensor(Y_train.values).float() #모든 데이터를 소수로 변경하는 코드 포함
print('전환 후: ', type(X_train))
# DNN 학습
begin = time()
print('\nDNN 학습 시작')
for epoch in range(MY_EPOCH): #현재 MY_EPOCH : 1000
output = model(X_train) # 하나하나 꺼내가며 순방향 계산 후 output에 저장 , 2차원 torch tensor 212, 1
if (epoch == 0):
print(X_train.shape)
print(output.shape)
#출력값 차원을 (212, 1) 에서 (212,)로 조정
output = torch.squeeze(output)
if (epoch == 0):
print(output.shape)
# 손실값 계산
loss = criterion(output, Y_train) # 손실값을 역전파로 사용 , 1차원 torch.tensor
# 손실값 출력
if (epoch % 10 == 0):
print('EPOCH : {:3},'.format(epoch),
'Loss : {:.3f}'.format(loss.item()))
# 역전파 알고리즘으로 가중치 보정
optimizer.zero_grad() # 기울기를 0으로 초기화하는 작업을 하는 함수
loss.backward() # 역전파 알고리즘을 부릅니다.
optimizer.step() # 시냅스의 보정치를 구하고 가중치를 더함
end = time()
print('\n최종 학습 시간 : {:.1f}초'.format(end - begin))
########## 인공 신경망 평가 #############
# 평가용 데이터 전환
# pandas dataframe ==> pytorch Tensor
X_test = torch.tensor(X_test.values).float()
# DNN으로 추측, 가중치 관련 계산 불필요
with torch.no_grad(): # 기울기 관련된 작업을 건너 뜀 , 평가시간, 메모리 절약 가능 , 자율 주행 차량에 대한 사고 방지 등
pred = model(X_test)
print(pred.flatten())
# 추측 결과 tensor를 numpy로 전환
pred = pred.numpy() # 91개의 심장병 결과를 확률로 저장
# 확률을 2진수로 전환 후 F1 점수 계산
pred = (pred > 0.5) # true false
# print(pred.flatten())
print('추측 값 : ', pred.flatten())
print('정답 : ', Y_train.flatten())
f1 = f1_score(Y_test, pred)
print('\n최종 정확도 (F1 점수): {:.3f}'.format(f1))
원본 데이터 샘플 10개
age sex cp trestbps chol fbs restecg thalach exang oldpeak slope \
0 63 1 3 145 233 1 0 150 0 2.3 0
1 37 1 2 130 250 0 1 187 0 3.5 0
2 41 0 1 130 204 0 0 172 0 1.4 2
3 56 1 1 120 236 0 1 178 0 0.8 2
4 57 0 0 120 354 0 1 163 1 0.6 2
5 57 1 0 140 192 0 1 148 0 0.4 1
6 56 0 1 140 294 0 0 153 0 1.3 1
7 44 1 1 120 263 0 1 173 0 0.0 2
8 52 1 2 172 199 1 1 162 0 0.5 2
9 57 1 2 150 168 0 1 174 0 1.6 2
ca thal target
0 0 1 1
1 0 2 1
2 0 2 1
3 0 2 1
4 0 2 1
5 0 1 1
6 0 2 1
7 0 3 1
8 0 3 1
9 0 2 1
원본 데이터 통계
age sex cp trestbps chol fbs \
count 303.000000 303.000000 303.000000 303.000000 303.000000 303.000000
mean 54.366337 0.683168 0.966997 131.623762 246.264026 0.148515
std 9.082101 0.466011 1.032052 17.538143 51.830751 0.356198
min 29.000000 0.000000 0.000000 94.000000 126.000000 0.000000
25% 47.500000 0.000000 0.000000 120.000000 211.000000 0.000000
50% 55.000000 1.000000 1.000000 130.000000 240.000000 0.000000
75% 61.000000 1.000000 2.000000 140.000000 274.500000 0.000000
max 77.000000 1.000000 3.000000 200.000000 564.000000 1.000000
restecg thalach exang oldpeak slope ca \
count 303.000000 303.000000 303.000000 303.000000 303.000000 303.000000
mean 0.528053 149.646865 0.326733 1.039604 1.399340 0.729373
std 0.525860 22.905161 0.469794 1.161075 0.616226 1.022606
min 0.000000 71.000000 0.000000 0.000000 0.000000 0.000000
25% 0.000000 133.500000 0.000000 0.000000 1.000000 0.000000
50% 1.000000 153.000000 0.000000 0.800000 1.000000 0.000000
75% 1.000000 166.000000 1.000000 1.600000 2.000000 1.000000
max 2.000000 202.000000 1.000000 6.200000 2.000000 4.000000
thal target
count 303.000000 303.000000
mean 2.313531 0.544554
std 0.612277 0.498835
min 0.000000 0.000000
25% 2.000000 0.000000
50% 2.000000 1.000000
75% 3.000000 1.000000
max 3.000000 1.000000
Index(['age', 'sex', 'cp', 'trestbps', 'chol', 'fbs', 'restecg', 'thalach',
'exang', 'oldpeak', 'slope', 'ca', 'thal'],
dtype='object')
학습용 입력 데이터 모양 : (212, 13)
학습용 출력 데이터 모양 : (212,)
평가용 입력 데이터 모양 : (91, 13)
평가용 출력 데이터 모양 : (91,)
전환 전 : <class 'numpy.ndarray'>
전환 후 : <class 'pandas.core.frame.DataFrame'>
정규화된 학습용 데이터 샘플 10개
age sex cp trestbps chol fbs restecg \
0 1.056198 -1.591645 -0.876941 -0.057207 1.159771 -0.437048 0.906057
1 -0.349346 -1.591645 -0.876941 -0.057207 1.201462 -0.437048 0.906057
2 -0.133108 0.628281 -0.876941 -0.461466 0.722018 -0.437048 0.906057
3 1.380554 0.628281 -0.876941 -1.789748 1.076389 -0.437048 -0.958837
4 -0.133108 0.628281 1.059637 -0.057207 -0.028417 2.288077 -0.958837
5 0.515604 0.628281 -0.876941 0.231550 -0.278561 -0.437048 0.906057
6 0.083129 0.628281 -0.876941 0.058296 2.202040 -0.437048 0.906057
7 0.731842 0.628281 1.059637 1.097821 -0.090953 2.288077 0.906057
8 -0.241227 0.628281 2.027926 1.213324 1.055544 2.288077 0.906057
9 0.839960 -1.591645 -0.876941 0.404805 0.972162 2.288077 0.906057
thalach exang oldpeak slope ca thal
0 -1.116087 -0.717137 0.727092 -0.643372 1.242340 -0.490357
1 -0.265429 1.394433 0.079430 -0.643372 -0.737931 1.084730
2 -2.264476 1.394433 0.727092 -0.643372 1.242340 1.084730
3 -0.988489 1.394433 -0.163443 -0.643372 1.242340 -0.490357
4 1.053091 -0.717137 -0.892062 0.999940 2.232475 -0.490357
5 0.542696 -0.717137 -0.487274 -0.643372 -0.737931 1.084730
6 -0.690758 1.394433 0.079430 -0.643372 0.252204 1.084730
7 -0.478094 1.394433 -0.082485 -0.643372 -0.737931 -0.490357
8 1.265755 -0.717137 0.079430 -0.643372 -0.737931 1.084730
9 -1.796614 -0.717137 0.646134 -0.643372 2.232475 -0.490357
정규화된 학습용 데이터 통계
age sex cp trestbps chol \
count 2.120000e+02 2.120000e+02 2.120000e+02 2.120000e+02 2.120000e+02
mean -5.341639e-17 2.388027e-16 -5.551115e-17 2.304236e-16 -2.518949e-16
std 1.002367e+00 1.002367e+00 1.002367e+00 1.002367e+00 1.002367e+00
min -2.727959e+00 -1.591645e+00 -8.769409e-01 -1.789748e+00 -2.425637e+00
25% -7.818211e-01 -1.591645e+00 -8.769409e-01 -6.347204e-01 -7.580053e-01
50% 1.371884e-01 6.282809e-01 -8.769409e-01 -5.720656e-02 -5.968468e-02
75% 7.318416e-01 6.282809e-01 1.059637e+00 5.203073e-01 7.063835e-01
max 2.353623e+00 6.282809e-01 2.027926e+00 3.985390e+00 3.536145e+00
fbs restecg thalach exang oldpeak \
count 2.120000e+02 2.120000e+02 2.120000e+02 2.120000e+02 2.120000e+02
mean 5.184532e-17 -1.183540e-16 1.550123e-16 -2.094760e-18 4.425181e-17
std 1.002367e+00 1.002367e+00 1.002367e+00 1.002367e+00 1.002367e+00
min -4.370483e-01 -9.588371e-01 -2.477140e+00 -7.171372e-01 -8.920622e-01
25% -4.370483e-01 -9.588371e-01 -7.332913e-01 -7.171372e-01 -8.920622e-01
50% -4.370483e-01 -9.588371e-01 1.173667e-01 -7.171372e-01 -2.444006e-01
75% -4.370483e-01 9.060571e-01 8.085264e-01 1.394433e+00 5.651764e-01
max 2.288077e+00 2.770951e+00 2.286545e+00 1.394433e+00 4.127315e+00
slope ca thal
count 2.120000e+02 2.120000e+02 2.120000e+02
mean -8.536149e-17 -8.326673e-17 -1.110223e-16
std 1.002367e+00 1.002367e+00 1.002367e+00
min -2.286684e+00 -7.379311e-01 -3.640533e+00
25% -6.433722e-01 -7.379311e-01 -4.903575e-01
50% -6.433722e-01 -7.379311e-01 -4.903575e-01
75% 9.999399e-01 2.522043e-01 1.084730e+00
max 9.999399e-01 3.222611e+00 1.084730e+00
DNN 요약
Sequential(
(0): Linear(in_features=13, out_features=1000, bias=True)
(1): Tanh()
(2): Linear(in_features=1000, out_features=1000, bias=True)
(3): Tanh()
(4): Linear(in_features=1000, out_features=1, bias=True)
(5): Sigmoid()
)
총 파라미터 수: 1,016,001
전환 전: <class 'pandas.core.frame.DataFrame'>
전환 후: <class 'torch.Tensor'>
DNN 학습 시작
torch.Size([212, 13])
torch.Size([212, 1])
torch.Size([212])
EPOCH : 0, Loss : 0.250
EPOCH : 10, Loss : 0.194
EPOCH : 20, Loss : 0.166
EPOCH : 30, Loss : 0.151
EPOCH : 40, Loss : 0.142
EPOCH : 50, Loss : 0.136
EPOCH : 60, Loss : 0.132
EPOCH : 70, Loss : 0.129
EPOCH : 80, Loss : 0.127
EPOCH : 90, Loss : 0.125
EPOCH : 100, Loss : 0.123
EPOCH : 110, Loss : 0.122
EPOCH : 120, Loss : 0.121
EPOCH : 130, Loss : 0.120
EPOCH : 140, Loss : 0.119
EPOCH : 150, Loss : 0.118
EPOCH : 160, Loss : 0.118
EPOCH : 170, Loss : 0.117
EPOCH : 180, Loss : 0.117
EPOCH : 190, Loss : 0.116
EPOCH : 200, Loss : 0.116
EPOCH : 210, Loss : 0.115
EPOCH : 220, Loss : 0.115
EPOCH : 230, Loss : 0.115
EPOCH : 240, Loss : 0.115
EPOCH : 250, Loss : 0.114
EPOCH : 260, Loss : 0.114
EPOCH : 270, Loss : 0.114
EPOCH : 280, Loss : 0.114
EPOCH : 290, Loss : 0.113
EPOCH : 300, Loss : 0.113
EPOCH : 310, Loss : 0.113
EPOCH : 320, Loss : 0.113
EPOCH : 330, Loss : 0.113
EPOCH : 340, Loss : 0.113
EPOCH : 350, Loss : 0.112
EPOCH : 360, Loss : 0.112
EPOCH : 370, Loss : 0.112
EPOCH : 380, Loss : 0.112
EPOCH : 390, Loss : 0.112
EPOCH : 400, Loss : 0.112
EPOCH : 410, Loss : 0.112
EPOCH : 420, Loss : 0.112
EPOCH : 430, Loss : 0.112
EPOCH : 440, Loss : 0.111
EPOCH : 450, Loss : 0.111
EPOCH : 460, Loss : 0.111
EPOCH : 470, Loss : 0.111
EPOCH : 480, Loss : 0.111
EPOCH : 490, Loss : 0.111
EPOCH : 500, Loss : 0.111
EPOCH : 510, Loss : 0.111
EPOCH : 520, Loss : 0.111
EPOCH : 530, Loss : 0.111
EPOCH : 540, Loss : 0.111
EPOCH : 550, Loss : 0.111
EPOCH : 560, Loss : 0.111
EPOCH : 570, Loss : 0.111
EPOCH : 580, Loss : 0.110
EPOCH : 590, Loss : 0.110
EPOCH : 600, Loss : 0.110
EPOCH : 610, Loss : 0.110
EPOCH : 620, Loss : 0.110
EPOCH : 630, Loss : 0.110
EPOCH : 640, Loss : 0.110
EPOCH : 650, Loss : 0.110
EPOCH : 660, Loss : 0.110
EPOCH : 670, Loss : 0.110
EPOCH : 680, Loss : 0.110
EPOCH : 690, Loss : 0.110
EPOCH : 700, Loss : 0.110
EPOCH : 710, Loss : 0.110
EPOCH : 720, Loss : 0.110
EPOCH : 730, Loss : 0.110
EPOCH : 740, Loss : 0.110
EPOCH : 750, Loss : 0.110
EPOCH : 760, Loss : 0.110
EPOCH : 770, Loss : 0.109
EPOCH : 780, Loss : 0.109
EPOCH : 790, Loss : 0.109
EPOCH : 800, Loss : 0.109
EPOCH : 810, Loss : 0.109
EPOCH : 820, Loss : 0.109
EPOCH : 830, Loss : 0.109
EPOCH : 840, Loss : 0.109
EPOCH : 850, Loss : 0.109
EPOCH : 860, Loss : 0.109
EPOCH : 870, Loss : 0.109
EPOCH : 880, Loss : 0.109
EPOCH : 890, Loss : 0.109
EPOCH : 900, Loss : 0.109
EPOCH : 910, Loss : 0.109
EPOCH : 920, Loss : 0.109
EPOCH : 930, Loss : 0.109
EPOCH : 940, Loss : 0.109
EPOCH : 950, Loss : 0.109
EPOCH : 960, Loss : 0.109
EPOCH : 970, Loss : 0.109
EPOCH : 980, Loss : 0.109
EPOCH : 990, Loss : 0.109
최종 학습 시간 : 9.3초
tensor([0.8684, 0.9066, 0.0191, 0.7368, 0.7261, 0.9879, 0.3274, 0.8890, 0.0124,
0.7724, 0.5673, 0.8853, 0.9531, 0.9865, 0.0749, 0.1096, 0.5546, 0.1254,
0.9485, 0.2357, 0.7851, 0.0233, 0.6288, 0.4982, 0.9016, 0.0135, 0.8440,
0.1974, 0.5552, 0.4753, 0.7729, 0.4345, 0.8401, 0.2612, 0.9234, 0.9836,
0.0342, 0.5913, 0.3235, 0.0031, 0.0106, 0.1367, 0.0529, 0.8307, 0.7674,
0.9225, 0.5222, 0.8355, 0.9718, 0.7948, 0.0442, 0.1610, 0.9905, 0.3084,
0.7292, 0.6263, 0.8606, 0.5370, 0.0106, 0.8981, 0.4665, 0.8083, 0.3638,
0.9253, 0.3848, 0.0725, 0.6847, 0.2738, 0.9652, 0.7040, 0.7867, 0.0227,
0.9579, 0.8522, 0.4886, 0.9142, 0.0137, 0.2161, 0.0078, 0.0228, 0.8955,
0.7737, 0.5455, 0.0568, 0.9631, 0.6561, 0.7666, 0.0068, 0.7081, 0.6765,
0.6866])
추측 값 : [ True True False True True True False True False True True True
True True False False True False True False True False True False
True False True False True False True False True False True True
False True False False False False False True True True True True
True True False False True False True True True True False True
False True False True False False True False True True True False
True True False True False False False False True True True False
True True True False True True True]
정답 : tensor([1., 0., 0., 0., 1., 1., 0., 1., 1., 0., 1., 0., 0., 1., 1., 0., 0., 0.,
0., 1., 0., 1., 0., 0., 1., 0., 1., 1., 1., 1., 1., 0., 1., 0., 1., 0.,
1., 0., 0., 1., 1., 0., 1., 0., 0., 0., 1., 1., 1., 1., 1., 1., 1., 1.,
0., 1., 0., 0., 0., 0., 1., 1., 0., 1., 1., 1., 0., 0., 0., 1., 0., 1.,
1., 1., 0., 1., 1., 1., 0., 0., 1., 0., 0., 1., 0., 0., 1., 1., 1., 1.,
0., 1., 1., 0., 1., 0., 0., 0., 0., 1., 0., 0., 1., 1., 1., 1., 1., 0.,
0., 1., 0., 0., 0., 1., 1., 1., 1., 0., 1., 0., 1., 0., 1., 1., 1., 0.,
1., 1., 1., 1., 0., 1., 0., 1., 1., 1., 1., 0., 1., 0., 0., 1., 0., 1.,
0., 0., 1., 1., 1., 0., 0., 1., 1., 0., 0., 0., 1., 1., 0., 1., 0., 1.,
0., 0., 0., 0., 1., 1., 1., 1., 0., 0., 0., 0., 1., 0., 0., 1., 1., 0.,
1., 1., 0., 1., 1., 0., 0., 1., 0., 1., 1., 1., 0., 0., 0., 0., 1., 0.,
1., 1., 0., 0., 0., 0., 0., 1., 0., 1., 0., 0., 1., 0.])
최종 정확도 (F1 점수): 0.899
Process finished with exit code 0
1-1. 임의의 수 씨앗 삭제
- 기계학습에서 가중치의 초기 값은 임의의 숫자로 출발
- 가중치의 출발점이 어디인지에 따라 도착점도 달라진다.
- 도착점이 달라지면 최종 정확도도 달라진다.
- 임의의 수 생성 알고리즘의 씨앗이 이를 예방해준다.
-> 매번 실행 때 같은 임의의 수를 생성
정확도 : 매번 실행시 변함
학습 시간 : 변화가 거의 없음
torch.manual_seed(111) # pytorch의 씨앗을 정함 임의의 수를 정하는 알고리즘, 랜덤 시드값을 주기 위함
import numpy as np
np.random.seed(111) # numpy의 랜덤 시드값, 임의의 수 생성 및 지정주석처리 해준다.

매번 동일한 정확도가 나왔었다.



매번 달라지게 된다. 학습시간은 9초로 늘 동일하다시피 했다.
1-2. 최적화 함수 Adam으로 변경
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # 최적화 함수 Adam결과는 다음과 같다.
시간 11.3초, F1점수 0.875
시간은 오래 걸리고 정확도는 떨어진 것을 알 수 있다.
2-1. 최적화 알고리즘 교체
SGD 최적화 함수는 대부분 상용 최적화 알고리즘의 원조
RMSprop은 최적화 도중 학습율을 상황에 맞게 조절하는 기술을 SGD에 추가
RMSprop은 SGD보다 진화된 알고리즘
정확도 : 상승 예상
학습 시간 : 상승 예상
optimizer = torch.optim.RMSprop(model.parameters(), lr=0.01) # 최적화 함수 RMSProp최종 학습 시간 : 10.1초
최종 정확도 (F1 점수): 0.855
| 학습시간 | 정확도 | |
| SGD | 9.1초 | 0.899 |
| RMSProp | 10.1초 | 0.855 |
| Adam | 11.3초 | 0.875 |
학습 시간은 1.1초 증가 , 정확도는 하락
3-1. 은닉층 추가
현재 DNN은 뉴런 1,000개 짜리 두개의 은닉층을 가짐
여기에 5,000개 짜리 하나를 추가하면?
심층 신경망에서 은닉층의 숫자가 많을수록 손실 값은 감소함
보정해야할 가중치의 수도 늘어나서 학습 시간이 늘어남
가중치 증가
정확도 증가
model = nn.Sequential(
nn.Linear(INPUT_DIM, MY_HIDDEN), # 입력층 , 첫번째 은닉층 추가 , 13 , 1000 , multiply Accumulate (선형 1차 방정식)
nn.Tanh(),
nn.Linear(MY_HIDDEN, MY_HIDDEN), # 두번째 은닉층 뉴런 계산
nn.Tanh(),
# 은닉층 5000 추가
nn.Linear(MY_HIDDEN, 5000),
nn.Tanh(),
nn.Linear(5000, 1), # 은닉층이 추가 된 최종 출력층
# nn.Linear(MY_HIDDEN, 1), # 최종 출력층은 하나
nn.Sigmoid()
)코드를 이렇게 변경
3-2. 은닉층 삭제
2번째 은닉층을 삭제해보자.
model = nn.Sequential(
nn.Linear(INPUT_DIM, MY_HIDDEN), # 입력층 , 첫번째 은닉층 추가 , 13 , 1000 , multiply Accumulate (선형 1차 방정식)
nn.Tanh(),
# nn.Linear(MY_HIDDEN, MY_HIDDEN), # 두번째 은닉층 뉴런 계산
# nn.Tanh(),
# 은닉층 5000 추가
# nn.Linear(MY_HIDDEN, 5000),
# nn.Tanh(),
# nn.Linear(5000, 1), # 은닉층이 추가 된 최종 출력층
nn.Linear(MY_HIDDEN, 1), # 최종 출력층은 하나
nn.Sigmoid()
)| 파라미터 수 | Time | 정확도 | |
| Basic | 1,016,001 | 9.1초 | 0.899 |
| +5000 | 6,025,001 | 48.0초 | 0.901 |
| 두번째 뉴런 삭제 | 15,001 | 0.9초 | 0.891 |
파라미터 수는 500만개가 증가했고 시간은 5.5배가 증가했지만 정확도는 0.002가 늘어났다.
기대한 것에 비해 상승량은 많이 부족했다.
기존의 DNN이 충분한 크기라는 결론이기도 하다.
두번째 뉴런을 삭제하니 파라미터 수는 줄었는데 정확도가 매우 적게 감소했고 시간은 10배 빨라졌다.
기존에 선택한 파라미터 수에 늘리는것보다는 영향력이 크지만 정확도는 엄청난 차이는 아니었다.
4-1. 활성화 함수 교체
Tanh 활성화 함수는 뉴런 출력 값을 [-1, 1]로 조정
- 심장병 데이터는 Z-점수 정규화 처리를 함 (평균 0, 표준편차 1)
- 두 가지 (입력 데이터와 뉴런 출력값) 범위가 비슷
- ReLU는 뉴런 출력값을 [0, 무한대]로 조정
# PyTorch DNN을 Sequential 모델로 구현
model = nn.Sequential(
nn.Linear(INPUT_DIM, MY_HIDDEN), # 입력층 , 첫번째 은닉층 추가 , 13 , 1000 , multiply Accumulate (선형 1차 방정식)
# nn.Tanh(),
nn.ReLU(),
nn.Linear(MY_HIDDEN, MY_HIDDEN), # 두번째 은닉층 뉴런 계산
# nn.Tanh(),
nn.ReLU(),
# 은닉층 5000 추가
# nn.Linear(MY_HIDDEN, 5000),
# nn.Tanh(),
# nn.Linear(5000, 1), # 은닉층이 추가 된 최종 출력층
nn.Linear(MY_HIDDEN, 1), # 최종 출력층은 하나
nn.Sigmoid()
)
Tanh -> Sigmoid로 변경
model = nn.Sequential(
nn.Linear(INPUT_DIM, MY_HIDDEN), # 입력층 , 첫번째 은닉층 추가 , 13 , 1000 , multiply Accumulate (선형 1차 방정식)
# nn.Tanh(),
# nn.ReLU(),
nn.Sigmoid(),
nn.Linear(MY_HIDDEN, MY_HIDDEN), # 두번째 은닉층 뉴런 계산
# nn.Tanh(),
# nn.ReLU(),
nn.Sigmoid(),
# 은닉층 5000 추가
# nn.Linear(MY_HIDDEN, 5000),
# nn.Tanh(),
# nn.Linear(5000, 1), # 은닉층이 추가 된 최종 출력층
nn.Linear(MY_HIDDEN, 1), # 최종 출력층은 하나
nn.Sigmoid()
)| Parameter | Time | 정확도 | |
| Tanh | 1,016,001 | 9.1초 | 0.899 |
| ReLU | 1,016,001 | 10.2초 | 0.937 |
| Sigmoid | 1,016,001 | 9.4초 | 0.879 |
ReLU에서 대폭적인 정확도 향상이 있었다.
예상하는 것과 다른 결과가 나오기에 추측만으로 결론을 짓기보다는 딥러닝에서는 실습하면서 데이터를 쌓는 것이 중요하다.
5-1. 데이터 정규화 삭제
Z-점수 정규화는 머신러닝에 사용된 14개의 모든 요소들을 Z-점수화를 한다.
이로 인해 14개의 요소간의 영향력을 비슷하게 만든다.
이를 건너 뛰면 숫자가 큰 요소들의 중요성이 커진다.
# 입력 데이터 Z-점수 정규화
# 결과는 numpy의 n-차원 행렬 형식
scaler = StandardScaler() # StandardScaler를 짧게 정의
# X_train = scaler.fit_transform(X_train) # fit_transform을 사용해서 13개의 요소를 한번에 Z-점수 평균화 진행
# X_test = scaler.fit_transform(X_test) # 평가용 데이터에도 같은 Z-점수 평균화 진행
print('전환 전 : ', type(X_train))
# 호환이 완벽하지 않아서 자료 형변환이 필요함정규화 부분을 주석 처리

정규화를 하지 않아서 범위가 그대로인 것을 알 수 있다.
X_train, X_test, Y_train, Y_test = \
train_test_split(X_data, Y_data, test_size=0.3) # 데이터를 무작위로 추출
샘플이 뒤섞여 있는 것을 알 수 있는데 이는 30%를 섞고 추출했기 때문이다.
이번에는 StandardScalar를 MinMaxScalar로 변경해보자
# scaler = StandardScaler() # StandardScaler를 짧게 정의
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()| Parameter | Time | 정확도 | |
| Basic | 1,016,001 | 9.1초 | 0.899 |
| Z-점수 정규화 Erase | 1,016,001 | 9.0초 | 0.667 |
| MinMaxScaler | 1,016,001 | 8.8초 | 0.876 |
정확도가 떨어지고 시간은 비슷했다.
6-1. 데이터 요소 제거
Dataset에서 어떤 요소는 기게 학습에 방해된다.
fbs(공복혈당)과 chol(좋은 콜레스테롤) 두 요소에서 특이점 다수 발견
INPUT_DIM = 11 # 두개 요소를 삭제
# 데이터를 입력과 출력으로 분리
X_data = raw.drop('target', axis=1)
# 심장병 fbs, chol 삭제
X_data.drop('fbs', axis=1, inplace=True) # axis = 1 : 열
X_data.drop('chol', axis=1, inplace=True)trestbps와 ca도 추가 삭제
# 데이터를 입력과 출력으로 분리
X_data = raw.drop('target', axis=1)
# 심장병 fbs, chol 삭제
# X_data.drop('fbs', axis=1, inplace=True) # axis = 1 : 열
# X_data.drop('chol', axis=1, inplace=True)
# 심장병 trestbps, ca도 삭제
# X_data.drop('trestbps', axis=1, inplace=True) # axis = 1 : 열
# X_data.drop('ca', axis=1, inplace=True)| Parameter | Time | 정확도 | |
| Basic | 1,016,001 | 9.1초 | 0.899 |
| chol, fbs 삭제 | 1,014,001 | 9.0초 | 0.919 |
| trestbps, ca도 삭제 | 1,012,001 | 8.8초 | 0.867 |
Parameter는 데이터가 준만큼 줄어들었다.
시간은 매우 근소하게 감소했고
튀는 값이 얼마나 있냐에 따라서 정확도의 변화가 관찰되었다. 많이 튀는 값인 chol, fbs는 기계학습 정확도 향상을 가져왔고 trestbps, ca는 기계학습 확률에 도움 되는 지표였기에 빼버리자 정확도가 감소하게 되었다.
7-1. 데이터 누락
기계 학습에 있어 데이터의 양과 질이 기계학습의 성패를 크게 좌우함
데이터에서 처음 100만 사용하면 그만큼 정확도에 나쁜 영향을 미침
하지만 학습 시간은 그에 따라 감소
# 데이터 100개만 사용
raw.drop(raw.index[100:], inplace=True) # inplace 옵션을 사용
raw = raw.drop(raw.index[100:]) # inplace가 싫으면 다시 드랍해서 받으면 된다.| count | Data | Time | 정확도 | |
| Basic | 303 | (212, 13) | 9.1초 | 0.899 |
| Data = 100 | 100 | (70, 13) | 4.4초 | 1.000 |
처음 100개만 사용시에 데이터는 100개로 감소
정확도는 0.899 -> 1.000으로 증가
학습시간은 4.4초로 감소
데이터가 줄었는데 왜 정확도가 올랐는가?
데이터 자체에 문제가 있었던 것이다. 100개의 데이터 모두 심장병 환자 데이터뿐이었다. (예외 데이터가 없기 때문에 1.0) 무의미한 학습이다.
새로운 데이터를 추가하면 그에 따라서 시간은 늘어나고 정확도는 변화할 것이다.
하지만 이와 관련된 지식이 없기에 데이터셋 추가는 무리가 있다고 생각하고 넘어갑니다.
추후 인공지능 GAN으로 추가한다면 모를까 임의의 데이터를 넣는 것은 학습에 무의미하다고 생각합니다.
실습을 다 한 소스코드
# 파이썬 패키지 수입
import pandas as pd # pandas는 2차원 테이블에 특화된 패키지 (행,열 구성)
import matplotlib.pyplot as plt # 그래프 그릴 때 사용
import seaborn as sns # matplot 과 연동 flot을 만들어 줌
from time import time # 총 걸린 시간 계산
import torch
from torch import nn # torch -> nn use 층 구조 제공
from sklearn.model_selection import train_test_split # 심장병 데이터를 학습용, 평가용으로 나눌 때 사용
from sklearn.preprocessing import StandardScaler # Z점수 정규화를 할 때 사용
from sklearn.metrics import f1_score # 정확도를 판단할 때 사용
# 하이퍼 파라미터
INPUT_DIM = 13 # 총 14개의 파라미터 중 13개가 입력 요소
# INPUT_DIM = 11 # 두개 요소를 삭제
# INPUT_DIM = 9 # 두개 요소를 더 삭제
MY_HIDDEN = 1000 # DNN의 은닉 층에서 몇개를 사용할 지 결정 (DNN 규모)
MY_EPOCH = 1000 # 몇 번 반복해서 학습할 것인지 지정
# 추가 옵션 정리
# 1. 임의의 수 씨앗 삭제
# - 기계학습에서 가중치의 초기 값은 임의의 숫자로 출발
# - 가중치의 출발점이 어디인지에 따라 도착점도 달라진다.
# - 도착점이 달라지면 최종 정확도도 달라진다.
# - 임의의 수 생성 알고리즘의 씨앗이 이를 예방해준다.
# -> 매번 실행 때 같은 임의의 수를 생성
pd.set_option('display.max_columns', None) # pandas의 display.max_columns 옵션을 off , 기본 값은 on,
# pandos가 dataframe을 출력 할 때 생략해버림, 생략 없이 하기 위해서 끔
torch.manual_seed(111) # pytorch의 씨앗을 정함 임의의 수를 정하는 알고리즘, 랜덤 시드값을 주기 위함
import numpy as np
np.random.seed(111) # numpy의 랜덤 시드값, 임의의 수 생성 및 지정
# 데이터 파일 읽기
# 결과는 pandas의 데이터 프레임 형식
raw = pd.read_csv('heart.csv')
# 데이터 100개만 사용
# raw.drop(raw.index[100:], inplace=True) # inplace 옵션을 사용
# raw = raw.drop(raw.index[100:]) # inplace가 싫으면 다시 드랍해서 받으면 된다.
# 데이터 원본 출력
print('원본 데이터 샘플 10개')
print(raw.head(10))
print('원본 데이터 통계')
print(raw.describe()) # 통계를 보여주는 describe
# 데이터를 입력과 출력으로 분리
X_data = raw.drop('target', axis=1)
# 심장병 fbs, chol 삭제
# X_data.drop('fbs', axis=1, inplace=True) # axis = 1 : 열
# X_data.drop('chol', axis=1, inplace=True)
# 심장병 trestbps, ca도 삭제
# X_data.drop('trestbps', axis=1, inplace=True) # axis = 1 : 열
# X_data.drop('ca', axis=1, inplace=True)
Y_data = raw['target']
names = X_data.columns # 데이터의 이름들을 따와서 저장
print(names)
# 데이터를 학습용과 평가용으로 분리
X_train, X_test, Y_train, Y_test = \
train_test_split(X_data, Y_data, test_size=0.3) # 데이터를 무작위로 추출
# 최종 데이터 모양
print('\n학습용 입력 데이터 모양 : ', X_train.shape)
print('학습용 출력 데이터 모양 : ', Y_train.shape)
print('평가용 입력 데이터 모양 : ', X_test.shape)
print('평가용 출력 데이터 모양 : ', Y_test.shape)
# 입력 데이터 Z-점수 정규화
# 결과는 numpy의 n-차원 행렬 형식
scaler = StandardScaler() # StandardScaler를 짧게 정의
# from sklearn.preprocessing import MinMaxScaler
# scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train) # fit_transform을 사용해서 13개의 요소를 한번에 Z-점수 평균화 진행
X_test = scaler.fit_transform(X_test) # 평가용 데이터에도 같은 Z-점수 평균화 진행
print('전환 전 : ', type(X_train))
# 호환이 완벽하지 않아서 자료 형변환이 필요함
# numpy에서 pandas로 전환
# header 복구가 필요 => 그래서 names를 미리 따둬야 한다.
X_train = pd.DataFrame(X_train, columns=names)
X_test = pd.DataFrame(X_test, columns=names)
print('전환 후 : ', type(X_train))
# 정규화 된 학습용 데이터 출력
# count : 갯수 , mean : 평균, std : 표준편차 : 거의 1
print('\n정규화된 학습용 데이터 샘플 10개')
print(X_train.head(10))
print('정규화된 학습용 데이터 통계')
print(X_train.describe())
# 학습용 데이터 상자 그림
sns.set(font_scale=2)
# sns.boxplot(data=X_train, palette="colorblind")
# plt.show()
# PyTorch DNN을 Sequential 모델로 구현
model = nn.Sequential(
nn.Linear(INPUT_DIM, MY_HIDDEN), # 입력층 , 첫번째 은닉층 추가 , 13 , 1000 , multiply Accumulate (선형 1차 방정식)
nn.Tanh(),
# nn.ReLU(),
# nn.Sigmoid(),
nn.Linear(MY_HIDDEN, MY_HIDDEN), # 두번째 은닉층 뉴런 계산
nn.Tanh(),
# nn.ReLU(),
# nn.Sigmoid(),
# 은닉층 5000 추가
# nn.Linear(MY_HIDDEN, 5000),
# nn.Tanh(),
# nn.Linear(5000, 1), # 은닉층이 추가 된 최종 출력층
nn.Linear(MY_HIDDEN, 1), # 최종 출력층은 하나
nn.Sigmoid()
)
# DNN 요약
print('\nDNN 요약')
print(model)
# 총 파라미터 수 계산
total = sum(p.numel() for p in model.parameters())
print('총 파라미터 수: {:,}'.format(total))
# 최적화 함수와 손실함수 지정
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 최적화 함수 SGD
# optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # 최적화 함수 Adam
# optimizer = torch.optim.RMSprop(model.parameters(), lr=0.01) # 최적화 함수 RMSProp
criterion = nn.MSELoss() # 손실함수 MSE 지정
# 학습용 데이터 전환
# pandas dataframe에서 Pytorch 텐서로
print('전환 전: ', type(X_train))
X_train = torch.tensor(X_train.values).float() #모든 데이터를 소수로 변경하는 코드 포함
Y_train = torch.tensor(Y_train.values).float() #모든 데이터를 소수로 변경하는 코드 포함
print('전환 후: ', type(X_train))
# DNN 학습
begin = time()
print('\nDNN 학습 시작')
for epoch in range(MY_EPOCH): #현재 MY_EPOCH : 1000
output = model(X_train) # 하나하나 꺼내가며 순방향 계산 후 output에 저장 , 2차원 torch tensor 212, 1
if (epoch == 0):
print(X_train.shape)
print(output.shape)
#출력값 차원을 (212, 1) 에서 (212,)로 조정
output = torch.squeeze(output)
if (epoch == 0):
print(output.shape)
# 손실값 계산
loss = criterion(output, Y_train) # 손실값을 역전파로 사용 , 1차원 torch.tensor
# 손실값 출력
if (epoch % 10 == 0):
print('EPOCH : {:3},'.format(epoch),
'Loss : {:.3f}'.format(loss.item()))
# 역전파 알고리즘으로 가중치 보정
optimizer.zero_grad() # 기울기를 0으로 초기화하는 작업을 하는 함수
loss.backward() # 역전파 알고리즘을 부릅니다.
optimizer.step() # 시냅스의 보정치를 구하고 가중치를 더함
end = time()
print('\n최종 학습 시간 : {:.1f}초'.format(end - begin))
########## 인공 신경망 평가 #############
# 평가용 데이터 전환
# pandas dataframe ==> pytorch Tensor
X_test = torch.tensor(X_test.values).float()
# DNN으로 추측, 가중치 관련 계산 불필요
with torch.no_grad(): # 기울기 관련된 작업을 건너 뜀 , 평가시간, 메모리 절약 가능 , 자율 주행 차량에 대한 사고 방지 등
pred = model(X_test)
print(pred.flatten())
# 추측 결과 tensor를 numpy로 전환
pred = pred.numpy() # 91개의 심장병 결과를 확률로 저장
# 확률을 2진수로 전환 후 F1 점수 계산
pred = (pred > 0.5) # true false
# print(pred.flatten())
print('추측 값 : ', pred.flatten())
print('정답 : ', Y_train.flatten())
f1 = f1_score(Y_test, pred)
print('\n최종 정확도 (F1 점수): {:.3f}'.format(f1))'Study > Deep Learning' 카테고리의 다른 글
| RNN 시계열로 추측해보는 감자 가격 (0) | 2022.05.12 |
|---|---|
| PyTorch 02. MNIST (0) | 2022.02.11 |
| PyTorch 01. Basic PyTorch (0) | 2022.02.11 |
| Pytorch 00. Hello Pytorch (0) | 2022.02.11 |
| [Tensorflow] 04. RNN - AirLine (0) | 2022.01.26 |



