
Rylah's Study & Daily Life
[Tensorflow] 04. RNN - AirLine 본문
이 항목은 Tensorflow 2.3 / Keras 2.4.3로 진행하는데 오류 해결이 어떤 버전을 해도 안되고 문서도 없다.
LSTM 관련 공부는 사진으로 대체하겠다.
Traceback (most recent call last):
File "C:/rudududdfh/pyCharmWorkspace/my-TF/airline/airline.py", line 114, in <module>
model.add(LSTM(MY_UNIT)) # LSTM을 모델에 추가 , MY_UNIT 하이퍼 파라미터 사용, LSTM의 차원
File "C:\ProgramData\Anaconda3\envs\TF-inter\lib\site-packages\tensorflow\python\training\tracking\base.py", line 457, in _method_wrapper
result = method(self, *args, **kwargs)
File "C:\ProgramData\Anaconda3\envs\TF-inter\lib\site-packages\tensorflow\python\keras\engine\sequential.py", line 221, in add
output_tensor = layer(self.outputs[0])
File "C:\ProgramData\Anaconda3\envs\TF-inter\lib\site-packages\tensorflow\python\keras\layers\recurrent.py", line 663, in __call__
return super(RNN, self).__call__(inputs, **kwargs)
File "C:\ProgramData\Anaconda3\envs\TF-inter\lib\site-packages\tensorflow\python\keras\engine\base_layer.py", line 926, in __call__
input_list)
File "C:\ProgramData\Anaconda3\envs\TF-inter\lib\site-packages\tensorflow\python\keras\engine\base_layer.py", line 1117, in _functional_construction_call
outputs = call_fn(cast_inputs, *args, **kwargs)
File "C:\ProgramData\Anaconda3\envs\TF-inter\lib\site-packages\tensorflow\python\keras\layers\recurrent_v2.py", line 1108, in call
inputs, initial_state, _ = self._process_inputs(inputs, initial_state, None)
File "C:\ProgramData\Anaconda3\envs\TF-inter\lib\site-packages\tensorflow\python\keras\layers\recurrent.py", line 862, in _process_inputs
initial_state = self.get_initial_state(inputs)
File "C:\ProgramData\Anaconda3\envs\TF-inter\lib\site-packages\tensorflow\python\keras\layers\recurrent.py", line 646, in get_initial_state
inputs=None, batch_size=batch_size, dtype=dtype)
File "C:\ProgramData\Anaconda3\envs\TF-inter\lib\site-packages\tensorflow\python\keras\layers\recurrent.py", line 2524, in get_initial_state
self, inputs, batch_size, dtype))
File "C:\ProgramData\Anaconda3\envs\TF-inter\lib\site-packages\tensorflow\python\keras\layers\recurrent.py", line 2968, in _generate_zero_filled_state_for_cell
return _generate_zero_filled_state(batch_size, cell.state_size, dtype)
File "C:\ProgramData\Anaconda3\envs\TF-inter\lib\site-packages\tensorflow\python\keras\layers\recurrent.py", line 2984, in _generate_zero_filled_state
return nest.map_structure(create_zeros, state_size)
File "C:\ProgramData\Anaconda3\envs\TF-inter\lib\site-packages\tensorflow\python\util\nest.py", line 635, in map_structure
structure[0], [func(*x) for x in entries],
File "C:\ProgramData\Anaconda3\envs\TF-inter\lib\site-packages\tensorflow\python\util\nest.py", line 635, in <listcomp>
structure[0], [func(*x) for x in entries],
File "C:\ProgramData\Anaconda3\envs\TF-inter\lib\site-packages\tensorflow\python\keras\layers\recurrent.py", line 2981, in create_zeros
return array_ops.zeros(init_state_size, dtype=dtype)
File "C:\ProgramData\Anaconda3\envs\TF-inter\lib\site-packages\tensorflow\python\util\dispatch.py", line 201, in wrapper
return target(*args, **kwargs)
File "C:\ProgramData\Anaconda3\envs\TF-inter\lib\site-packages\tensorflow\python\ops\array_ops.py", line 2747, in wrapped
tensor = fun(*args, **kwargs)
File "C:\ProgramData\Anaconda3\envs\TF-inter\lib\site-packages\tensorflow\python\ops\array_ops.py", line 2794, in zeros
output = _constant_if_small(zero, shape, dtype, name)
File "C:\ProgramData\Anaconda3\envs\TF-inter\lib\site-packages\tensorflow\python\ops\array_ops.py", line 2732, in _constant_if_small
if np.prod(shape) < 1000:
File "<__array_function__ internals>", line 6, in prod
File "C:\ProgramData\Anaconda3\envs\TF-inter\lib\site-packages\numpy\core\fromnumeric.py", line 3052, in prod
keepdims=keepdims, initial=initial, where=where)
File "C:\ProgramData\Anaconda3\envs\TF-inter\lib\site-packages\numpy\core\fromnumeric.py", line 86, in _wrapreduction
return ufunc.reduce(obj, axis, dtype, out, **passkwargs)
File "C:\ProgramData\Anaconda3\envs\TF-inter\lib\site-packages\tensorflow\python\framework\ops.py", line 848, in __array__
" a NumPy call, which is not supported".format(self.name))
NotImplementedError: Cannot convert a symbolic Tensor (lstm/strided_slice:0) to a numpy array. This error may indicate that you're trying to pass a Tensor to a NumPy call, which is not supported
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
# 파이썬 패키지 가져오기
import pandas as pd # 2차원 데이터 특화
import numpy as np # n차원 행렬
import matplotlib.pyplot as plt # 데이터 시각화
import seaborn as sns # 데이터 시각화
from time import time # 시간 측정
from sklearn.preprocessing import MinMaxScaler # 데이터 정규화
# RNN 구현용
from keras.models import Sequential # 순차적인 인공신경망 만들 때 사용
from keras.layers import InputLayer, Dense # 입력층을 구현 / 인공 신경망의 각 층을 연결할 때 사용
from keras.layers import LSTM
from keras.layers import Embedding
# 하이퍼 파라미터
MY_PAST = 12 # 시 계열 데이터 중 몇 개의 숫자를 입력 값으로 사용할 지 정함 / 12달치의 여행자 수를 RNN의 입력 값으로 사용,
# 13번째 달의 여행자수를 예측
MY_SPLIT = 0.8 # 데이터를 얼마만큼 학습용으로 사용할 것인지 결정, 0.8 == 80%
MY_UNIT = 300 # LSTM 안의 내부의 차원 수를 결정함
MY_SHAPE = (MY_PAST, 1) # keras LSTM은 2차원 데이터, LSTM 입력으로 들어갈 데이터의 모양
MY_EPOCH = 300 # 반복 학습 수
MY_BATCH = 64 # 병렬 계산 데이터 수
np.set_printoptions(precision=3) # 소수점 3번째 자리까지 출력
# 데이터 파일 읽기
# 결과는 pandas의 데이터 프레임 형식
raw = pd.read_csv('airline.csv',
header=None,
usecols=[1]) # 날짜는 사용하지 않고, 여행객 수만 사용하기 위해 1번째 cols 사용
# 시계열 데이터 시각화
# plt.plot(raw)
# plt.show()
# 데이터 원본 출력
print('원본 데이터 샘플 13개')
print(raw.head(13))
print('\n원본 데이터 통계')
print(raw.describe())
# MinMax 데이터 정규화 이론
# 데이터를 [0, 1]로 스케일링 x = x - min(x) / max(x) - min(x)
# 특이점이 많은 데이터에서는 힘이 약해진다. (Outlier)
# 가장 인기 있는 정규화 Z점수수 정규화(StandardScaler), MinMaxScaler, RobustScaler, Normalizer
# RobustScaler : 아웃라이어에 약한 MinMax 단점 개선
# Normalizer : 데이터의 크기보다 방향이 더 중요한 경우에 사용한다.
# MinMax 데이터 정규화
scaler = MinMaxScaler()
s_data = scaler.fit_transform(raw)
print('\nMinMax 정규화 형식:', type(s_data)) #data는 numpy로 전환된다.
# 정규화 데이터 출력
df = pd.DataFrame(s_data)
print('\n정규화 데이터 샘플 13개')
print(df.head(13))
print('\n정규화 데이터 통계')
print(df.describe())
# 13개 묶음으로 데이터 분할
# 결과는 python 리스트
bundle = []
for i in range(len(s_data) - MY_PAST):
bundle.append(s_data[i: i+MY_PAST+1]) # i ~ MY_PAST 슬라이싱
# 데이터 분할 결과 확인
print('\n총 13개 묶음의 수:', len(bundle))
print(bundle[0])
print(bundle[1])
# numpy로 전환
print('분할 데이터의 타입:', type(bundle))
bundle = np.array(bundle)
print('분할 데이터의 모양:', bundle.shape)
# 데이터를 입력과 출력으로 분할
x_data = bundle[:, 0:MY_PAST]
y_data = bundle[:, -1]
# 데이터를 학습용과 평가용으로 분할
split = int(len(bundle) * MY_SPLIT)
x_train = x_data[: split]
x_test = x_data[split:]
y_train = y_data[: split]
y_test = y_data[split:]
# 최종 데이터 모양
print('\n학습용 입력 데이터 모양:', x_train.shape)
print('학습용 출력 데이터 모양:', y_train.shape)
print('평가용 입력 데이터 모양:', x_test.shape)
print('평가용 출력 데이터 모양:', y_test.shape)
########## 인공 신경망 구현 ##########
# RNN 구현
# 케라스 RNN은 2차원 입력만 허용
model = Sequential() # 순차적으로 데이터를 불러온다.
model.add(InputLayer(input_shape=MY_SHAPE)) # 입력층을 지정한다. MY_SHAPE 2차원 데이터
# model.add(Embedding(input_dim=MY_PAST, output_dim=1))
# LSTM 오류가 안잡힌다. 나중에 계속 해야된다.
model.add(LSTM(MY_UNIT)) # LSTM을 모델에 추가 , MY_UNIT 하이퍼 파라미터 사용, LSTM의 차원
model.add(Dense(1, activation='sigmoid'))
print('\nRNN 요약')
model.summary()
########## 인공 신경망 학습 ##########
# 최적화 함수와 손실 함수 지정
model.compile(optimizer='rmsprop',
loss='mse')
begin = time()
print('\nRNN 학습 시작')
model.fit(x_train,
y_train,
epochs=MY_EPOCH,
batch_size=MY_BATCH,
verbose=0)
end = time()
print('총 학습 시간: {:.1f}초'.format(end - begin))
########## 인공 신경망 평가 ##########
# RNN 평가
loss = model.evaluate(x_test,
y_test,
verbose=0)
print('최종 MSE 손실값: {:.3f}'.format(loss))
# RNN 추측
pred = model.predict(x_test)
pred = scaler.inverse_transform(pred)
pred = pred.flatten().astype(int)
print('\n추측 결과 원본:', pred)
# 정답 역전환
truth = scaler.inverse_transform(y_test)
truth = truth.flatten().astype(int)
print('\n정답 원본:', truth)
# line plot 구성
axes = plt.gca()
axes.set_ylim([0, 650])
sns.lineplot(data=pred, label='pred', color='blue')
sns.lineplot(data=truth, label='truth', color='red')
plt.show()
# 예제 동작에 실패함!
파란색은 예측값이고 붉은색은 실제 값이다.

1. 경사하강법 변경
- 사용한 RMSprop은 경사하강법의 한계를 개선한 알고리즘이다.
- Step 사이즈, 즉 학습률을 하나의 숫자로 고정하지 않는다.

총 학습시간 21.1초
최종 MSE 손실값 0.011
a) SGD
- 고전적인 경사하강법
- RMSprop이 학습률을 고정하지 않고 하므로 손실값이 증가할 것이고, 학습시간이 감소할 것이다.
compile(optimizer='rmsprop') => compile(optimizer='sgd')
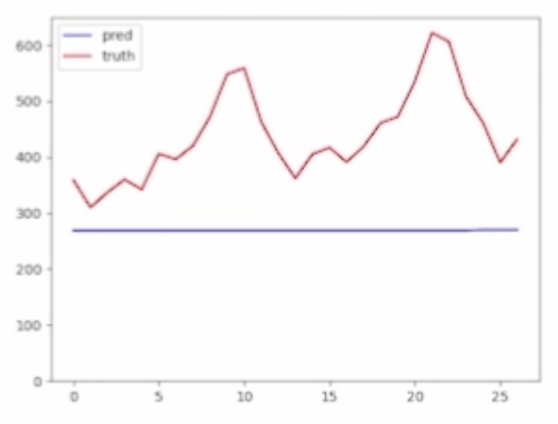

총 학습시간 20.6초
최종 MSE 손실값 0.131
시간은 그대로인데 오차가 약 12배 이상 난다.
b) Adam
- 예제가 동작하면 추후 작성
2. 활성화 함수 교체
- Tanh 함수는 [-1, 1] 사이로 출력값 범위를 전환한다.
- LSTM은 tanh와 sigmoid를 둘 다 사용한다.
- Keras에서는 tanh 하나만 사용한다.
a) None (제거)
- model.add(LSTM(MY_UNIT)) => model.add(LSTM(MY_UNIT, activation=None))

총 학습시간 20.7초
최종 MSE 손실값 0.017
MSE 결과가 나빠지고 학습시간은 거의 그대로이다.
그래프는 거의 그대로이다.
b) Linear
- model.add(LSTM(MY_UNIT)) => model.add(LSTM(MY_UNIT, activation=linear))
추후 작성
3. LSTM 구조 변경
- MY_UNIT은 LSTM 셀의 차원 수
- 출력 값의 숫자 = 다음 단으로 넘기는 데이터의 숫자
- LSTM 값을 줄이면 규모가 줄어든다.ㅏ
a) MY_UNIT = 50
- MY_UNIT = 300 => 50

Total Params 362,701 => 10,451 30배로 감소
학습 시간 21 -> 8.8
MSE 0.011 -> 0.014 아주 작게 증가
50으로도 어느정도의 기계학습이 가능했다.
30배로 줄어든 경우 가벼워진다는 장점이 있지만, 작은 MSE 차이로 큰 변화를 겪는 데이터도 있으니 무조건 과신해서는 안된다.
b) MY_UNIT = 10
더 줄어들었으니 더 그래프가 완만해지는 경향을 보일 것인데 얼마나 큰 영향일지는 돌려봐야 알 것이다.
4. 과거 데이터 조정
- MY_PAST 파라미터를 조정
- MY_PAST는 몇달치 과거 데이터를 보고 다음 달의 여행객을 예상하는 것이다.
- 12는 12개월, 24는 24개월
- MY_PAST 수치에 따라 LSTM의 Unroll 횟수가 결정된다.
a) MY_PAST = 12 => 24

- Total Params = 그대로 유지
- 학습시간 21 -> 38.9
- MSE 0.011 -> 0.019
- 그래프는 경향성은 비슷하나 디테일한 곡선이 다르고 간격이 증가했다.
b) MY_PAST = 12 => 6
반대일거 같다.
5. 학습용 데이터 조정
- MY_SPLIT 파라미터는 데이터에서 몇%를 학습용으로 취할지 정한다.
- 0.8 은 80% 0.5는 50%
- 숫자를 줄인다면 더 적은 학습 데이터로 LSTM을 학습하고 평가용 데이터로 LSTM을 평가하는 것
a) MY_SPLIT = 0.8 => 0.5

- 데이터 모양 105 / 27 -> 66 / 66
- 학습시간 21 -> 16.9
- MSE 0.011 -> 0.069 (5배)
- 그래프가 매우 완만해졌다.
b) MY_SPLIT 0.8 => 0.9
마치 80% -> 90%로 학습용 데이터가 늘어서 더 정확해질거 같지만 큰 차이가 나지 않고 학습 시간은 길어질 것 같다.
왜냐하면 평가용 데이터가 그만큼 줄어들기 때문에 평가용 데이터의 상태에 따라 오차가 크게 발생할 수 있기 때문이다.
6. 데이터 정규화 교체
- MinMax 스케일링은 데이터를 [0, 1] 범위로 정규화
- Z-점수 스케일링 (Standard 스케일링)은 데이터의 평균은 0 표준편차는 1로 정규화
- 실제로 돌려봐서 결과를 통해 손실값을 비교해봐야 알 수 있다.
- LSTM 안에 활성화 함수는 Tanh와 sigmoid 사용
- 활성화 함수 수치 범위로 인해 MinMax가 좀 더 나아 보임
a) MinMax => Z점수 정규화
- from sklearn.preprocessing import StandardScaler 추가
- scaler = StandardScaler()로 변경

- Params 동일
- 시간은 거의 동일
- MSE 0.011 => 0.583 약 56배 증가
- 그래프 두 선사이의 간격도 매우 증가했다.
b) 데이터 정규화 생략
- 예전에 Z점수 정규화를 안했던거 처럼 값이 커짐에 따라 비중이 달라져서 크게 오차가 날 것이다.
7. 데이터 스케일링 조정
- air passenger 데이터는 MinMax 스케일링, 즉 [0,1]로 정규화
- LSTM tanh의 출력 값 범위는 [-1, 1]
- [-1, 1]로 스케일링 하면 Tanh와 범위가 일치함
- [-1, 1] => [0, 1] * 2 - 1 => [0, 2] - 1 => [-1, 1]
a) [0, 1] => [-1, 1]
s_data = s_data * 2 - 1 # 행렬 모든 숫자를 연산하는데 한줄이 필요
데이터는 실제로 -1 ~ 1로 변경됨

- 학습시간 거의 동일
- MSE 0.011 -> 0.181 약 17배 증가
- 그래프가 평행을 이루듯이 나아감
b) scikit-learn -> RobustScaler
- 정규화는 -1 ~ 1 동일
- 출력 뉴런을 tanh로 활성화
해결이 될까?
돌려봐야 알 것이다.
'Study > Deep Learning' 카테고리의 다른 글
| PyTorch 01. Basic PyTorch (0) | 2022.02.11 |
|---|---|
| Pytorch 00. Hello Pytorch (0) | 2022.02.11 |
| [TensorFlow] 03. CNN - Fashion Items (0) | 2022.01.26 |
| [TensorFlow] 02. DNN - Boston House Value (0) | 2022.01.23 |
| [TenserFlow] 01. MNIST (0) | 2022.01.22 |



