
Rylah's Study & Daily Life
Modern C++ : 03. C++ Build : Assembly 본문
|
1
2
3
4
5
6
7
8
9
|
double multiply(double a, double b)
{
return a * b;
}
double divide(double a, double b)
{
return a / b;
}
|
cs |

complier 옵션에 -S(대문자)를 주게 되면 .s 파일이 생성된다.
이 코드를 텍스트 편집기로 열어보면 다음과 같이 나오게 되고 이는 어셈블리어로 볼 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
.file "005.assembly.cpp"
.text
.globl _Z8multiplydd
.type _Z8multiplydd, @function
_Z8multiplydd:
.LFB0:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movsd %xmm0, -8(%rbp)
movsd %xmm1, -16(%rbp)
movsd -8(%rbp), %xmm0
mulsd -16(%rbp), %xmm0
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size _Z8multiplydd, .-_Z8multiplydd
.globl _Z6dividedd
.type _Z6dividedd, @function
_Z6dividedd:
.LFB1:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movsd %xmm0, -8(%rbp)
movsd %xmm1, -16(%rbp)
movsd -8(%rbp), %xmm0
divsd -16(%rbp), %xmm0
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1:
.size _Z6dividedd, .-_Z6dividedd
.ident "GCC: (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:
|
cs |
이를 모두 읽어볼 필요는 없다.
multiplydd라는 함수에서 mulsd라는 것을 사용해서 연산 후 return 해준다는 것을 알 수 있다.
하지만 이는 매우 불편하다.
리눅스에서는 Complier Explorer로 이를 확인하기 쉽다.
Compiler Explorer
godbolt.org
컴파일러 익스플로러에서는 다양한 옵션 혹은 컴파일러를 통해 어셈블리어를 확인해볼 수 있다.
위 코드를 GCCx86-64에 넣어서 확인하면 다음과 같이 나온다.

컴파일러의 최적화를 확인해보자
|
1
2
3
4
5
6
7
8
9
10
|
unsigned int num8x(unsigned int a)
{ //multiply by 8
return a * 8;
}
unsigned int num8x_2(unsigned int a)
{
//multiply by 8
return a << 3;
}
|
cs |
예를 들어 다음과 같이 8을 곱하는 함수가 있다고 가정해보자.
첫 번째 함수는 말 그대로 8배를 하는 값을 return 하는 것이고, 두번째 함수는 bit shift로 3번 left shift 해주는 것으로 8배를 구현해준다.
몇몇 사람들은 비트 쉬프트 연산이 편리한게 아니라 더 속도가 좋다고 이야기하기도 한다.
과연 어셈블리어로는 어떻게 나올까?

gcc -O0로 컴파일 했을 때 나온 결과이다.

gcc -O2로 했을 때의 결과이다.
어떤 컴파일 옵션을 돌려도 어셈블리 코드로 동일하게 동작함을 알 수 있다.
두 함수는 차이가 없다. * 8로 짜는 것이 가독성이 더 좋을 것이다.
|
1
2
3
4
5
6
7
8
9
10
|
int divide (int a, int b)
{
return a / b;
}
int divideBy13 (int a)
{
return a / 13;
}
|
cs |
그렇다면 나누기에 대해서 한번 보도록 해보자.
보통 나누기를 한다면 저렇게 함수를 짜게 될 것이다.
그리고 13으로 나누게 된다면 이렇게 짜야할 것이다.
어셈블리어는 어떨까?
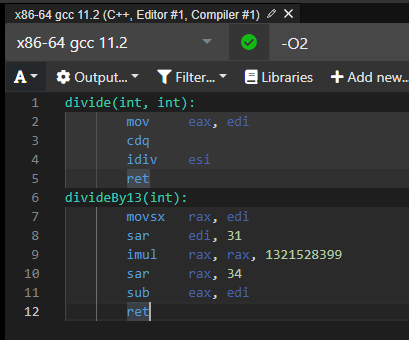
위와 같이 차이가 나게 되는데 divideBy13이 길이가 더 길다고 느린거 아닌가요? 라고 물어볼 수 있다.
하지만 내부적으로 idiv라는 어셈블리어와 imul이라는 어셈블리어의 동작 속도 차이로 인해 아래 함수가 더 속도가 빠르다는 것을 알 수 있다. (약 5배 차이가 난다고 한다.)
이번에는 if-else와 switch문에서 어셈블리를 알아보자
코드는 다음과 같다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
int test(int a)
{
if (a == 0)
return a * 0;
else if (a == 1)
return a;
else if (a == 3)
return a / 4;
else if (a == 4)
return 5;
return 0;
}
int test2(int a)
{
switch (a)
{
case 0: return a * 0;
case 1: return a;
case 3: return a / 4;
case 4: return 5;
default: return 0;
}
}
|
cs |
gcc로 컴파일 했을 때 어셈블리는 다음과 같다.

위가 if else이고 아래가 switch이다.
cmp 4까지 도달하는데 6개의 연산과 4개의 연산으로 switch 구문이 조금 더 연산이 빠르다는 것을 알 수 있다.
하지만 이것은 gcc 컴파일러에 대해서이다 다른 컴파일러는 어떨까?
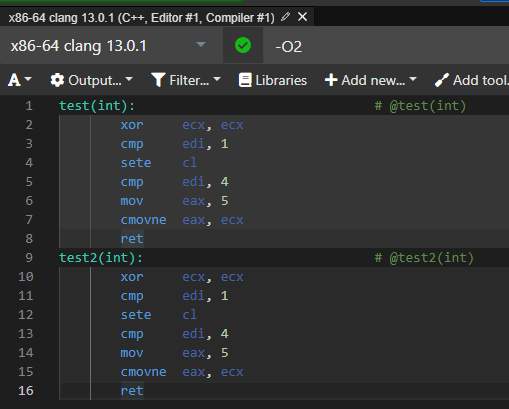
clang 컴파일러에서는 완벽하게 동일하게 동작함을 알 수 있다.

MSVC(Visual Studio)에서는 다음과 같다.
cmp 연산은 if-else가 더 많음을 알 수 있다.
큰 차이는 없어보이지만 미세한 차이가 있는 것 같다.
clang을 사용하면 같은 것을 알 수 있듯이 무조건적으로 switch 문이 효율적이라고 말하기는 어려울 것이다.
정리
| * 2 | * 4 | / 2 | / 4 |
| << 1 | << 2 | >> 1 | >> 2 |
이와 같이 나타내는 경우에서 두 동작이 같음을 확인 할 수 있었다.
| divide(a, b) | divideBy13(a) |
| div Assembly use (코드는 짧으나 느림) | mult를 이용해 구현(코드가 길지만 div 보다 빠름) |
| if else | switch, case |
| 컴파일러에 따라 다름 (clang에서는 동일) | 컴파일러에 따라 다름 (clang에서는 동일) |
가장 정확한 방법은 벤치마크를 돌려보는 것이 정확하다.
컴파일러에서는 가독성을 해치지 않게 짜도 어느정도 최적화 된 코드를 만들어주게 된다.
'Study > C++' 카테고리의 다른 글
| Modern C++ : 03. C++ Build : Debug (0) | 2022.03.14 |
|---|---|
| Visual Studio 단축키 (0) | 2022.03.14 |
| Modern C++ : 03. C++ Build : Extern & Static (0) | 2022.02.03 |
| Modern C++ : 03. C++ Build : PreProceccer - 프리프로세서 (0) | 2022.02.03 |
| Modern C++ : 03. C++ Build : Header File - 헤더 파일 (0) | 2022.02.03 |
